

Dev Logs: Tiny Tools for Even Tinier Teams
Inspired by Ben Torvaney and my own experience, let's attempt to answer the age old question: 'how do you kickstart your team's very own football data department without plenty of resources?'

As someone who has been sitting on the outside of the football data analytics world and looking in for the past few years, I have always amazed with what teams have done with data and finding new ways to gain an advantage. But that is only the case with European and American teams. When I look back at Asian football, I have the feeling that most of Asia is still very behind in terms of data analytics and there are teams and organisations who do not even have their own data department.
The most prominent example of an Asian club investing heavily into data (that I can think of) is Singapore’s Lion City Sailors, who receive the backing of a very popular e-commerce company in Shopee (yes, that Shopee with the Cristiano Ronaldo and Ronaldinho ads that might or might have not gone viral on social media). There might be a few more examples, but I cannot remember off the top of my head or have not come across at all. But, generally speaking, I think the main reason for this slow adaptation is the lack of direction and not knowing where to start.
Having been settled in my full-time data science/engineer role for almost a year now, I have had the chance to see and work with a full-scale data operation of a company, and it is mind-blowing, to say the least. Then, back in October of 2024 until around April of 2025, I got the chance to help building out the data side of a football organisation that I still cannot say the name of. That experience, even though it left me frustrated and heartbroken, taught me a lot and encouraged me to learn from the experience of many that have gone through the same path, hence the few ‘What I learned from…’ articles about the MIT Sloan Conference and the American Soccer Insights Summit earlier this year.
Since I might be on the outside of football again due to reasons beyond my control, I want to share what I have learned and my vision of building a data department in football with limited resources at hand, because that was the situation that I found myself in. This article is also inspired by Ben Torvaney’s original ‘Tools for tiny teams’ and Devin Pleuler’s ‘Big Data, Tiny Teams’, who are two of football analytics’ greats and have written two brilliant articles that I highly recommend adding to your reading list.
Housekeeping
A quick reminder that this article might be a bit different to what you would have normally seen from my blog. I do not have a big brain to come up with new metrics or introduce a new way to look at football data. However, my brain is big enough to learn new technologies and applications, then come up with a vision of how to automate football-focused processes while still retaining the human touch and observation in it.
I have already made my point about AI, and (again, long story short) while I think AI can be useful in some things, it is currently being overhyped and overrated (until it becomes rated). AI is just another tool, at the end of the day. The same goes with football, AI can definitely save time and human power in some processes like traversing through a mountain of tracking and event-level data, or generating data from tactical cam footage, or even translating data into the language that many coaches and players can understand (see Twelve Football’s work on this). But you cannot ‘vibe code’ with AI and expect it to build a whole data department, unless you want confidential data to leak out.
Once again, this is just my vision at the current time and I am sticking with what I have known so far. There are definitely better, cheaper options that I might not be aware of. As such, please feel free to let me know through a comment as I am always open to learning new things!
Tiny teams
Reinventing the wheel
This is one of the biggest lessons that I have learned on my journey so far and I have to credit Sébastian Coustou, formerly Parma Calcio’s head of data and analytics for this. The short answer to this is: no, you’re not.
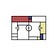
Unless your team are one of the leading teams in football analytics like Liverpool, Barcelona, or Ajax Amsterdam, you are not doing anything new, and especially when you are just starting out. Like Sébastian mentioned in his presentation below at PySport’s London meetup back in March of 2025, we (as a community) are standing on the shoulder of giants, and many teams and organisations have also worked with most of the ideas that you will come across. Fortunately, that is a good thing! Because those ideas are not new, it provides a great opportunity to learn from the mistakes and the experience that others have gone through, then you can come up with your own way of solving the same problem.
Another reason why you are not reinventing the wheel is, the same problems and questions that you are/will be asking, they have been asked plenty of times, just in a different form. Take this question that I had (and was inspired by Sébastian and the Parma data team’s work below), for example:
If I want to build a data pipeline that sends reports to players and coaches using WhatsApp while they are playing away in a different country and their phone number might not work, how can I still reach them in the same timeframe?
The question might sound new and that is because it is not widely used in football. But flip the question to, say, an e-commerce platform, then the question immediately becomes familiar.
How can my data pipeline reaches an existing customer and sends them promotions through WhatsApp without knowing where they are and as long as their phone number is still active?
This second question has been answered a long time ago and it is the reason why you still get text messages or ads through WhatsApp or other social platforms even though you might be on vacation in a different country. At its core, it is the same question, you will need to use the same technology and write the same code to answer the core question. The only difference between these questions is that each question is targeting a different audience. That is why you are not reinventing the wheel, because you are just asking questions in a football context. Flipping the question to something more familiar like daily shopping or social media platforms and the solution might just be right in front of you.
I do not remember whom this quote belongs to, but it is along the lines of ‘we all share the same data providers, we are all seeing the same numbers, the only difference is our process to get to those numbers’, and I cannot agree more. At the end of the day, if a striker overperforms his xG by about +3 xG, every team will be able to identify that. It does not matter if your data provider is Opta, or Statsbomb, or SkillCorner, or Wyscout. While there have been some research done into the differences between these providers, the general trend that ‘striker A significantly overperforms his xG’ still translates the same way across those providers, and any team who can identify that trend and capitalise the quickest is the one who will reap rewards, just like how Eintracht Frankfurt and Sturm Graz are reaping rewards of their strategy of buying undervalued strikers and sell them for a significant profit.
Embracing the open-source spirit
If you are not doing something new, then what is the point of keeping things behind a curtain? While confidentially still need to exist at a certain level and I agree with keeping completely fresh and new ideas or ideas that are club-funded or organisation-funded secret, the remaining ideas are either a remix of an old idea, or it is just an idea that has been forgotten over time. This is a more common phenomenon than one might think since it happens across different art forms, from painting, literature, to music. That is just how human’s creativity works, and there are really no new ideas, there are just new ways of doing things and seeing things.
With that in mind, why not embrace the open-source spirit, open the doors, and show a glimpse of what is being built? During the process of building your own department and try out new technologies, there will be times that you will run into problems. Document that problem-solving process and share it to others because you never know who you might inspire next, and you might even find the next talent who wants to join and/or collaborate with your team. Sharing ideas also opens the floor for better ideas or suggestions, and this can be very important because ‘tunnel vision’ happens quite frequently while working on those ideas and better ways of doing things might get ignored.
I really like what Sébastian and the Parma’s data & analytics team have done so far, and the fact that they are very happy to share their own inner-workings and processes have inspired me and given me a lot of ideas to work with. Their ‘Gialloblù Open Analytics Lab’ is also an inspiration for me to write this article, albeit without any team or organisation branding, this is just my own experience. Seeing what they have done made me feel inspired to go down the path of open-sourcing ideas and it has become one of my non-negotiables when it comes to working on football projects.
Tiny tools
Now that you have a decent idea of what to do with your data department, let’s take a look at the tools that are at your disposal. We are still embracing the open-source spirit here because, as stated at the beginning, we are working with very limited resources. That means, little money and little personnel. I will also follow Ben Torvaney’s flow in his article while adding what I know to keep the list updated.
Databases
Like Ben said in his article, “you can’t talk about databases without talking about SQL because SQL is the most boring technology around” (the boring technology part is inspired by Dan McKinley’s article). SQL has become so fundamental for databases that it will be the language of choice for anything database related. In terms of the software for managing databases, Ben suggested Postgres and dbt, and I still recommend Postgres as a free, open-source alternative.
However, my own platform of choice here will be Amazon Web Service, or AWS in short. AWS:
Offers more than just the ability to host a database instance as their tool suite is highly versatile for data-related tasks, from storing raw data files using S3 buckets to having a relational database using RDS/Aurora, and that is just scratching the surface.
Has become a lot more common since 2021, when Ben wrote his article, which means more community support, answers, and easy integration.
Will cost money, but does not cost a fortune and cost can be offset by using other available tools for different tasks. A free tier is also available for new starters, allow for free trialling and is scalable once the demands increases.
Supports most SQL flavours with their relational database service (RDS), including MySQL, NoSQL, PostgreSQL, MariaDB, allow for more technical flexibility and versatility when building out the database.
Has learning tutorials for both AWS and SQL widely available and on different platforms, from YouTube, Udemy or Coursera courses, to AWS’ official certificates.
Snowflake is another good data warehousing platform to consider and their tool suite is quite impressive, which includes Streamlit that I will talk about later. However, just like Ben’s advice, I would only consider Snowflake as an option if you are working with a decent amount of resources and a decently-sized team where you can afford to have someone who specialises in managing your database.
Source control & pipelines
After creating your own database instance, it is important to have a platform to source control your codes and projects. Why? Take this situation as an example:
After finishing a project and making updates to it, all of a sudden, you found that your latest update does not work and have created errors. Now, you want to roll back the previous version and keep your project online for relevant stakeholders, but then you realised that you have overwritten your old codes and there is no way to undo your code to its previous state. What do you do?
That is where source control platforms like Git comes in. Git…
Gives you cover by allowing you to roll back to the last version that you have saved.
Is free and open-source, with documentation, getting started guides, and community supports widely available.
Can integrate with a wide variety of applications to keep track of your codes and progress everywhere.
Allows for easy code collaboration between team members.
Gives user the ability to create different versions of the code within the same project (branch) or as a different project as a whole (fork) that can be recycled for different ideas or used to extend functionalities, without modifying the original version unless user gives permission (merge/pull request).
Monitors conflicts between the old and new versions of the project, prevents clashes when two or more people are working on the same project at the same time.
Also has free learning resources widely available on YouTube and on different learning platforms mentioned above.
Can work directly from the terminal, however can be tricky to remember and combine commands for new starters.
Along with Git, platforms like GitHub, GitLab, or Bitbucket are useful for hosting and storing codes and projects, either publicly or privately. Personally, I have not used Bitbucket before, and I found GitHub and GitLab to be fairly similar from what I got to work with. They…
Connect seamlessly with Git, allowing for direct upload of projects and codes without having to deal with complicated steps.
Provide an easy-to-use user interface that can be used to perform functionalities mentioned above without the need for using the terminal and remember Git commands.
Extend the ability to collaborate within the team with code comments, issues reporting, project workflow and monitoring.
Keep track of security vulnerabilities in real time and automatically check for new versions of required packages.
Make it easy to provide documentation for your projects through Markdown language.
Available with a free tier that contains most core functionalities, with the option to upgrade to a subscription for bigger demands for storages, runtime, and etc.
I have also used GitHub Desktop, which is GitHub’s an easy-to-use user interface that bypass the need of remembering and writing Git commands everytime I need to commit my codes onto GitHub. But the main reason why I am choosing these two platforms to talk about is their ability to also host data pipelines, or CI/CD pipelines, which is also available on your free account.
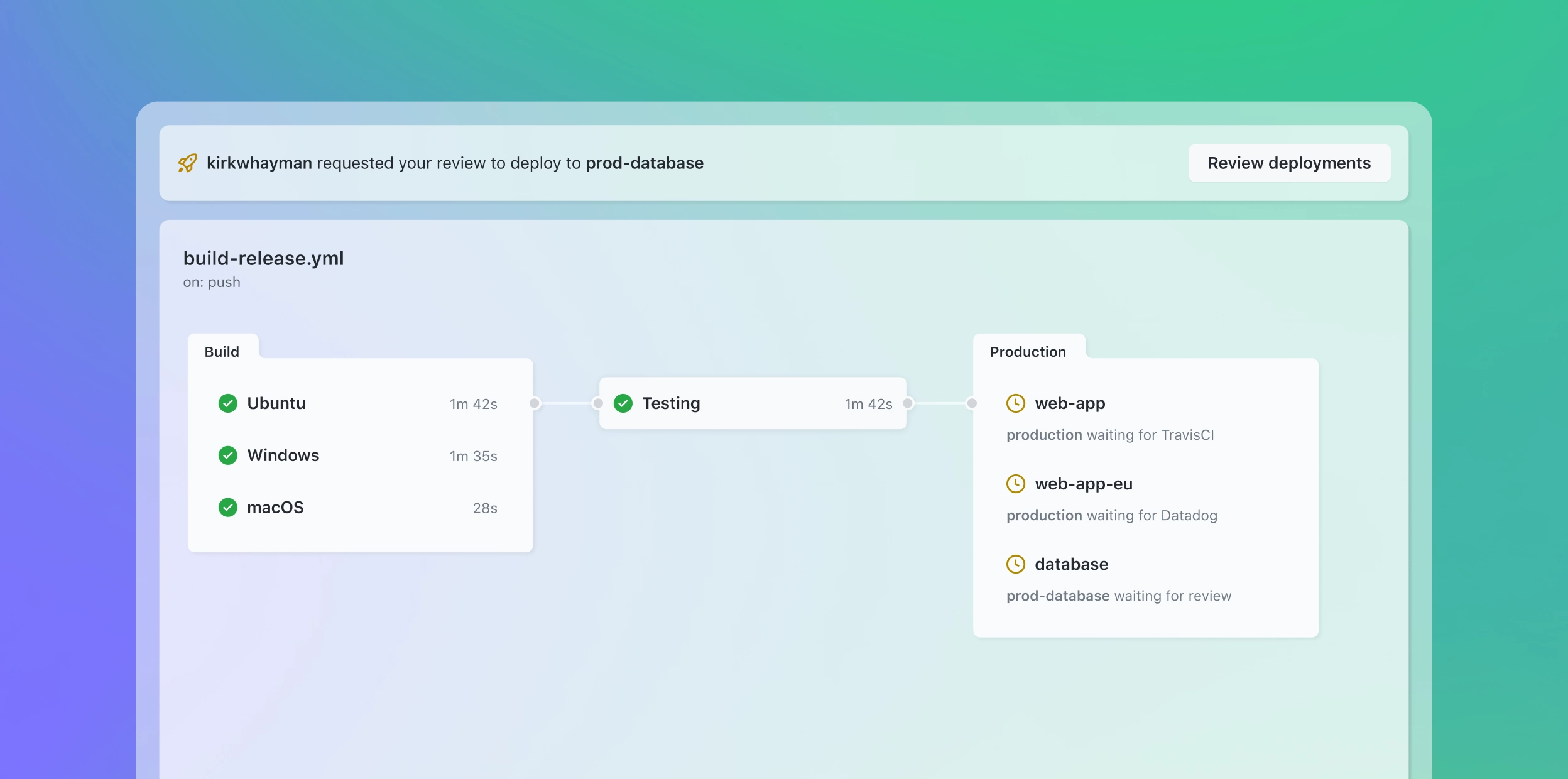
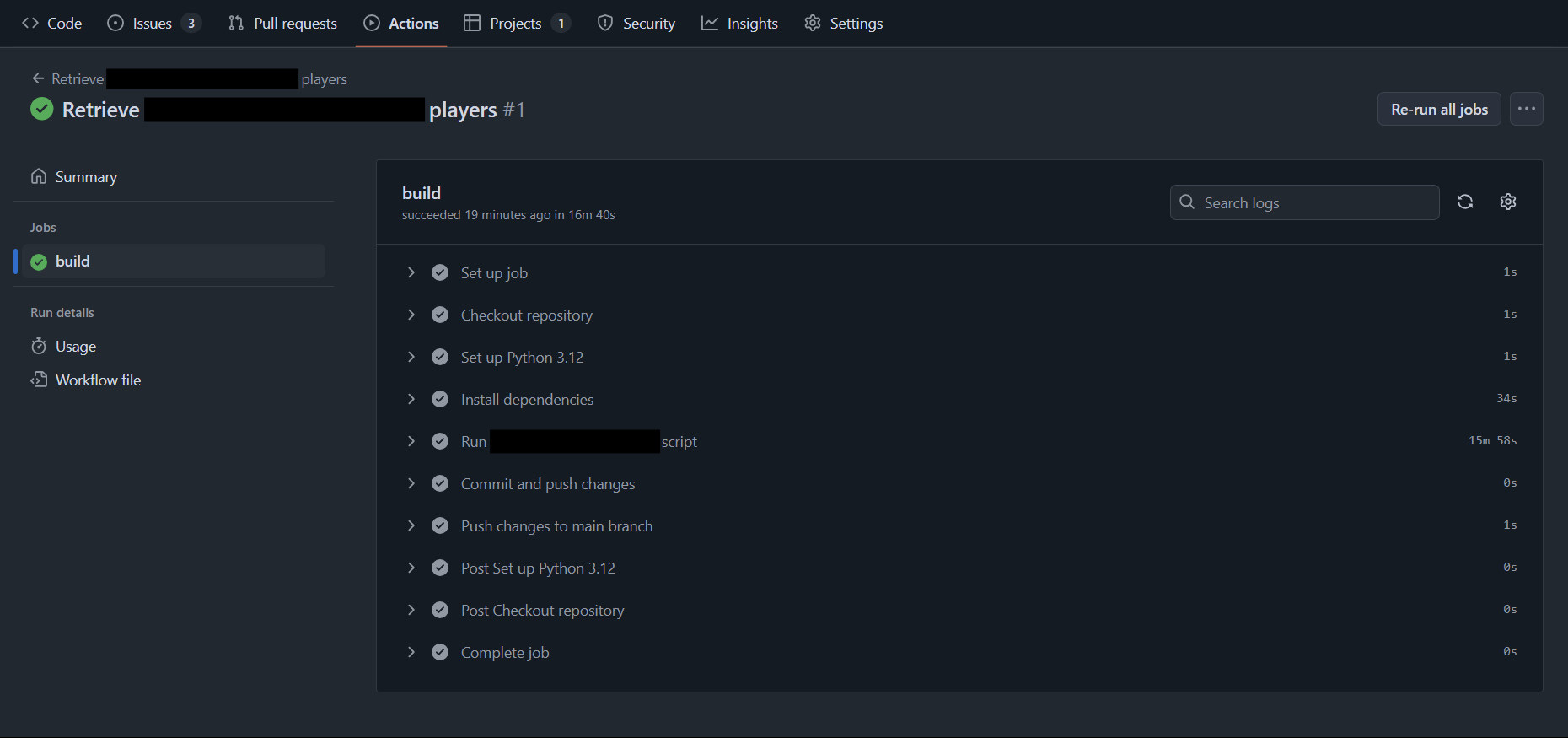
This was one of the functions that I pushed to be integrated into the workflow the heaviest when I worked with the [redacted] organisation earlier this year because I had seen what my full-time company had done with their existing pipelines. Thankfully, GitHub Actions made that process quite easy and I was able to set up a pipeline that scrape Transfermarkt for [redacted information] into an csv file that would be ready to be inserted into an existing PowerBI dashboard.
I am sure this was probably not the best way to do things, but here is a sneak peek of what I managed to build using GitHub Actions earlier this year! And, once again, this was done on a free account.
Web applications
This might be the part where most people dread the most because whenever ‘web apps’ gets brought up, people tend to think about using JavaScript and TypeScript to build and maintain them. While that is a logical step to do once the team has someone who has web developing skills and is also something that Ben recommended in his article, thankfully, the introduction of Streamlit for Python and ShinyApps for R have made this step a lot easier for non-experts. Since this is meant to be a getting started guide, I will stick with Streamlit as I am more familiar with the package and have made a few Streamlit dashboards over the years.
Streamlit…
Has significantly grown in popularity in the past few years and has developed a significant user base, thus has fairly extensive community supports around it.
Is available for free and open-source, with a detailed official documentation along with official and non-official guides widely available.
Can be easily installed using Python’s PIP package manager and is easy to set up locally with simple terminal commands.
Has started to officially support multipage web apps, allow for each app to contain multiple functionalities.
Can be slightly restricted as Streamlit’s default template is slightly hard to modify without using and knowing a combination of CSS and Markdown.
Apps are easily to be deployed and can be deployed through Streamlit Cloud and directly using a repository hosted on GitHub.
Is integrated into Snowflake’s tool suite and private apps can be deployed via Snowflake.
Since I did mention earlier that we will not be pursuing Snowflake unless we are working with a decent-sized budget, there is another free, open-source alternative deployment service that we can consider, which is ShinyProxy. This is an idea that I am borrowing from Lydia Jackson, Teamworks/Zelus Analytics’ Machine Learning Engineer, and her presentation at the American Soccer Insights Summit earlier this year. I believe that if the idea works for a leading sports analytics company like Zelus (now Teamworks), it can work for a tiny data team.
While Lydia mainly talked about deploying web apps built in R in her presentation, ShinyProxy can also host Streamlit apps, as per their official documentation and guides. ShinyProxy uses a small AWS EC2 instance for its server, which adds another reason to have an AWS package for your team, and the instance is not required to be huge either, thus will not add much to the overall AWS cost. Once again, I do not remember whom this quote is from (could be from Sébastian Coustou again or from Akshay Easwaran, formerly Atlanta United and now US Soccer Federation’s data engineer), but the amount of data that needs to be processed for a football organisation is nowhere near the sheer level of data that is being processed by an e-commerce company where hundreds, if not thousands, of customers are making transactions every minute. As such, the need for a large database or EC2 instance is very minimal.
The main purpose of having an EC2 instance along with ShinyProxy is to host web apps on the cloud, which allows for instant access whenever and whereever a relevant stakeholder needs. This can be a very important factor when giving the players and managers more control of their own data, since they should be able to access their performance and match data and have them at their own disposal. It allows for quicker decision-making process and saves valuable time for analysts who would usually have to spend a few hours in their workflow to process and visualise data.
Advanced web apps
This will be a short section, but if there is at least one member who has experience with web development in your team, I highly recommend working with TypeScript and React for maximum control of your web applications and dashboards. At times, Streamlit’s default template can be a bit limited if you want a customised web app and only uses Python to achieve such purpose.
TypeScript is pretty much similar to JavaScript, but it is more type-script. That means it requires the user to understand whether a function or module is taking an integer, a float, a string, or a specific type like a list/array, etc. It can be slightly overwhelming when moving from a dynamic language like Python to a strict language like TypeScript, but I have found being more type-strict is making my coding experience a lot easier, especially during the debugging phase. I am so used to being type-strict that I have also started doing the same in Python, which also supports that. I see the whole process like I am building a factory and connecting machines to each other, it is easier for me to know that machine A is specifically producing this product and machine B requires elements of this type, then I can link them together quite easily, instead of having to guess and make assumptions at every step of the way, which is a very frustrating experience from personal experiences.
Meanwhile, React is a user interface/front-end framework that supports both JavaScript and TypeScript. The framework gives you full control of building the interface for your web apps and starting from scratch, which can also be overwhelming for non-experts. But once the need for highly-customised web apps rises and Streamlit’s framework cannot support what you want to achieve, then it is probably a good time to migrate to TypeScript and React.
Other alternatives that I have seen being mentioned are Bootstrap, Vue.js, and Svelte. As with the nature of these frameworks, they are all free to install via NPM, JavaScript and TypeScript’s package manager, and are also open-source with extensive documentation and community support. Combining these frameworks with CSS and you will be able to build your own customised template, then combine it with server-side frameworks like ExpressJS to process user requests or anything that requires the server and you will have a fully-functional web app.
Maintenance
Once you have built and deployed your web apps, you will also need an application to maintain these apps and monitor for any errors or warnings that come out from them. EC2 only provides you with a cloud platform to host your web apps, ShinyProxy only eases your deployment process, and that is where Grafana steps in. Grafana…
Actually does more than logs management as it can also monitor up and down times of your apps, visualise runtime metrics, cost management, alerting, security and governance management, etc.
Is also available for free and open-source.
Also has a large user base providing extensive community support for all products that Grafana provides.
Is fairly easy to use with a simple user interface that houses all products and allows for easy switching between products.
Can help with identifying root cause of errors through logs and periods when your apps are extensively used through visualised metrics, along with other purposes that I have not worked with.
General theme
While I have tried to follow the general themes that Ben listed in his article, I have also added a few more of my own to this list.
Choosing free, open-source or low-cost applications to build out your tech stack.
There is no need to invest in technologies that will cost you a fortune while you cannot find the talents who can actively utilise and maintain them. Save yourself a fortune and invest that money into talents instead, because a good data analyst/scientist/engineer working with an average tech stack can still make magic happens.
Time is still your biggest constraint…
Going for open-source tools allows for more community support. If a tool is already widely used by a large user base, there is a higher chance that questions that you or your team might come across during the development process have already been asked and answered by the community, thus saving time plucking your hair and getting frustrated at how to solve this specific problem.
Invests in tools that save you time learning and utilising so you and your team can focus on the main purpose, which usually are tools that also already have a large user base. Rely on official, freely available documentation and guides to get you started, then improvise to adapt to your specific situation.
…but now, money is also a constraint.
Find the right balance between outsourcing and develop things in-house (also another borrowed advice from one of the conferences). Too much outsourcing can lead to a loss of control and overpaying for simple tech solutions, while too much in-house developing can lead to extra workload for your tiny team and unable to focus on the main tasks.
Spend the money on the talents, not on your tech stack. An organisation with the most advanced tech stack but without the right talents to utilise and maintain it is only using that tech stack to boast about their ability to spend money and all will go to waste in the end. The magic lies in the creativity and improvisation of the talents because, sometimes, an average tech stack can still create outstanding results when great people are utilising it.
Open the doors, even just a glimpse of it.
Currently, there is a huge difference between the advancements being made by the public sphere and people who are working at clubs. In fact, that difference is only getting bigger and bigger over time. There is only so much that passion and available knowledge can drive the public sphere to create new ideas. If clubs are willing to share a glimpse of what they are building and doing, just like Parma are doing right now, that can inspire so many people to build their own things and open the floor for new suggestions on how to improve football-centric processes.
Lastly, I want to write this article to prove that when people talk about football analytics, it is not just about looking at a bunch of numbers and then make assessments about them, and, honestly, anyone can do that. The true potential of football analytics in the next few years does not only lie in the data, but also in the process of how one team can generate quick, effective, unbiased insights that can aid their decision-making process. It is not about which providers we are getting the data from, because we all share them and we all collect data from the same matches anyway, it is about the process of how to get to those insights and who gets there the quickest.
This article might not be the most comprehensive guide and it might not even be as good as Ben Torvaney’s original article. However, I hope that this can be a decent starting guide for any team or organisation who want to start their own data department. Establishing a data culture can be a tough process at first, but once everything is in place, you will understand why many big clubs want to invest heavily in their data analytics department, and I hope this article can act as one of the starting points.